
The Memory Challenge
Traditional AI assistants suffer from digital amnesia. Each conversation starts fresh, forcing you to re-iterate all of the context that might be useful for conversation. Many language model providers have started to offer attempts to solve this problem – OpenAI recently has been experimenting with long term memory spread across different threads. The problem with these potential solutions is that they don't really get to the root of the problem: memory fragmentation.
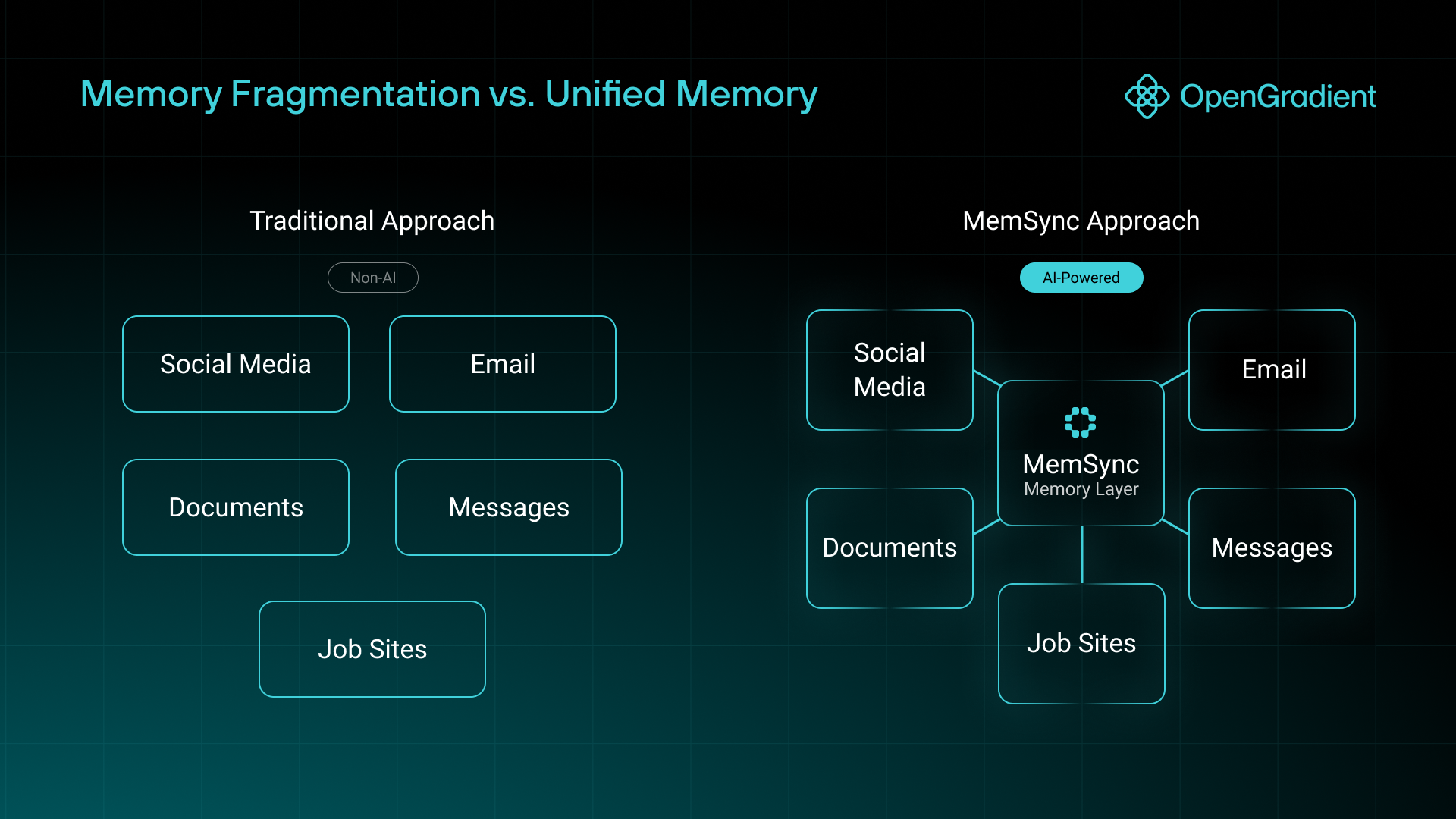
Social media, job sites, resumes, email, documents, and text messages all represent shards of who we are spread out across the internet. In order to really capture the essence of personality we have to look beyond singular sources of information and aggregate from the bigger picture. By only using messages gathered from chatGPT we create an unworkably narrow perspective of the user.
MemSync changes this by creating a persistent memory layer that travels with you across platforms and applications.
Building a Complete Memory System
MemSync focuses on being a portable yet powerful application that collects memories from a user's interactions online.
To create truly intelligent AI memory, we've broken down our approach into three core pillars:
1. Memory Collection - How we collect, structure, and store user information
2. Memory Formation - How we extract, consolidate, and manage insights from memories
3. Memory Retrieval - How we find and surface the right memories at the right time
Collection: Casting Lived Memory to Digital Memory
When designing our memory architecture, we thought it would make the most sense to mimic the organic psychology of human memory. In other words, how do we use our memories to approach everyday problems?
We use a series of methodologies to solve problems – things like pattern recognition, procedural automation of tasks, recency bias, etc. These have long been recognized and studied by psychologists from the 1970s to the modern day. What we found made the most sense for our memory system focused on the balance between short-term, event-based memories and long-term foundational knowledge about a user. This psychological grounding was something we felt was uniquely missing from the other memory approaches we saw in the market today, which emphasized unintuitive purely theoretical approaches.
Based on this philosophy, we separate and categorize memories into two types: semantic and episodic.
The Two Towers of Memory
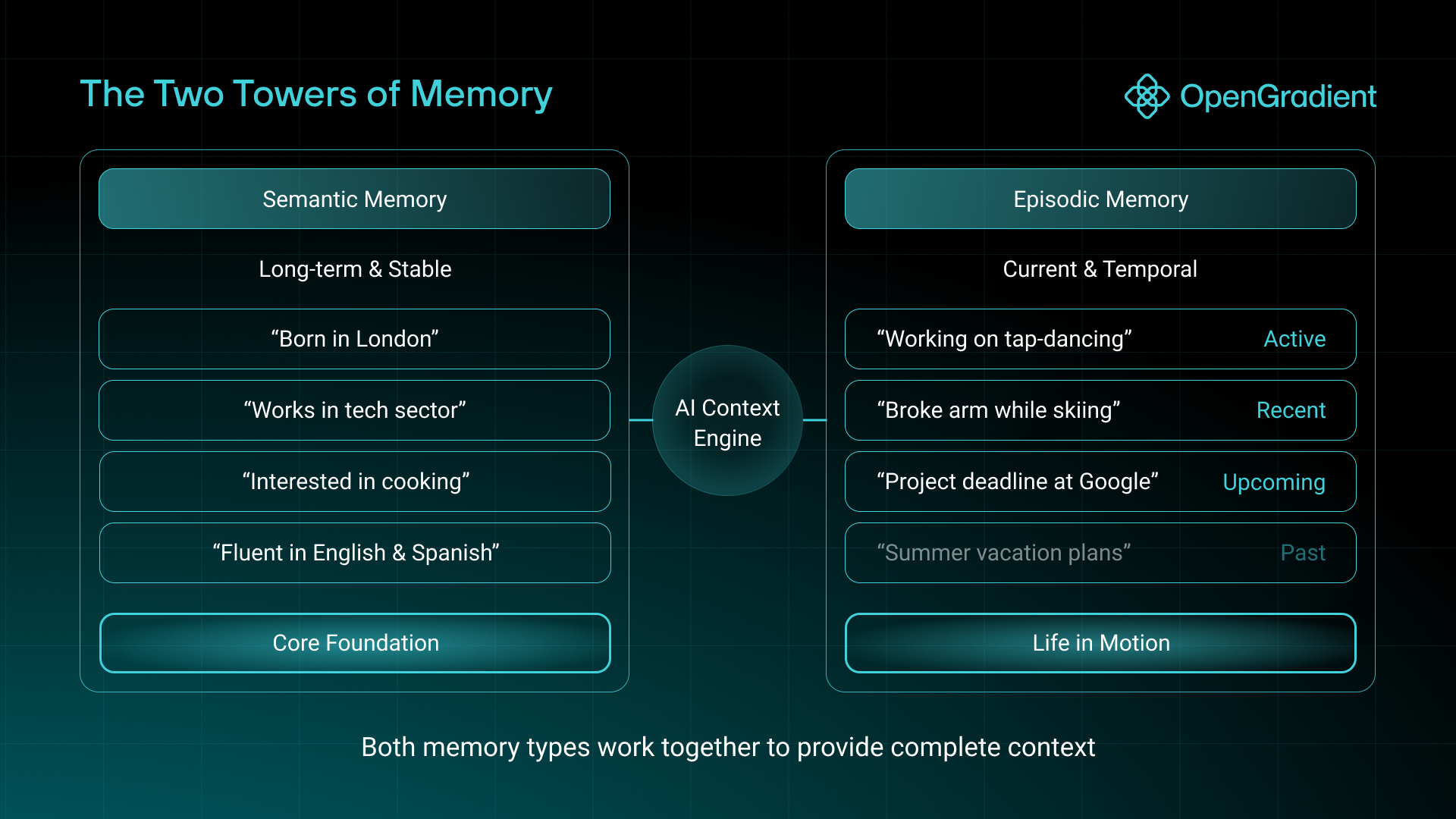
Semantic Memories are stable, long-term facts and characteristics – These form the core of your personality and upbringing.
Examples of semantic memories could include:
- Core identity information ("Born in London")
- Long term contextual information ("Works in the tech sector")
- Fundamental preferences and traits ("Interested in cooking")
- General facts not tied to time and place ("User is fluent in both English and Spanish")
These memories are an accumulation of a person's immutable traits. They should not frequently update, as they are not tied to temporary events and are more so meant as the foundation of one's character. They may also be subconscious drivers of our decisions. We don't often think about our upbringing or childhood, but they certainly play a role in how we respond to events in the present.
Episodic Memories capture your life in motion – These are current situations, active projects, and temporary circumstances, e.g.
- Current activities ("Working on tap-dancing skills")
- Recent events ("Broke my arm while skiing")
- Ongoing projects and goals ("I have a project deadline this upcoming week at Google")
These memories are often context and time specific. They may evolve and become naturally less relevant over time. We often keep a catalogue of recent events and interests in our mind. When we think about what we're going to do for the day, how we want to talk to our boss in the afternoon, or what hobby to keep practicing, it's these recent events that play a bigger role in our decision making.
When MemSync gathers and indexes information, it generates and organizes memories based on their best fit into one of these two types. This allows MemSync to differentiate between subconscious foundational memories and relevant temporal memories in its infrastructure. And unlike flat memory stores that treat all information equally, this dual-memory architecture gives us the flexibility to treat each of these memory archetypes uniquely for a more complete user image.
Smart Consolidation of Individual Memories
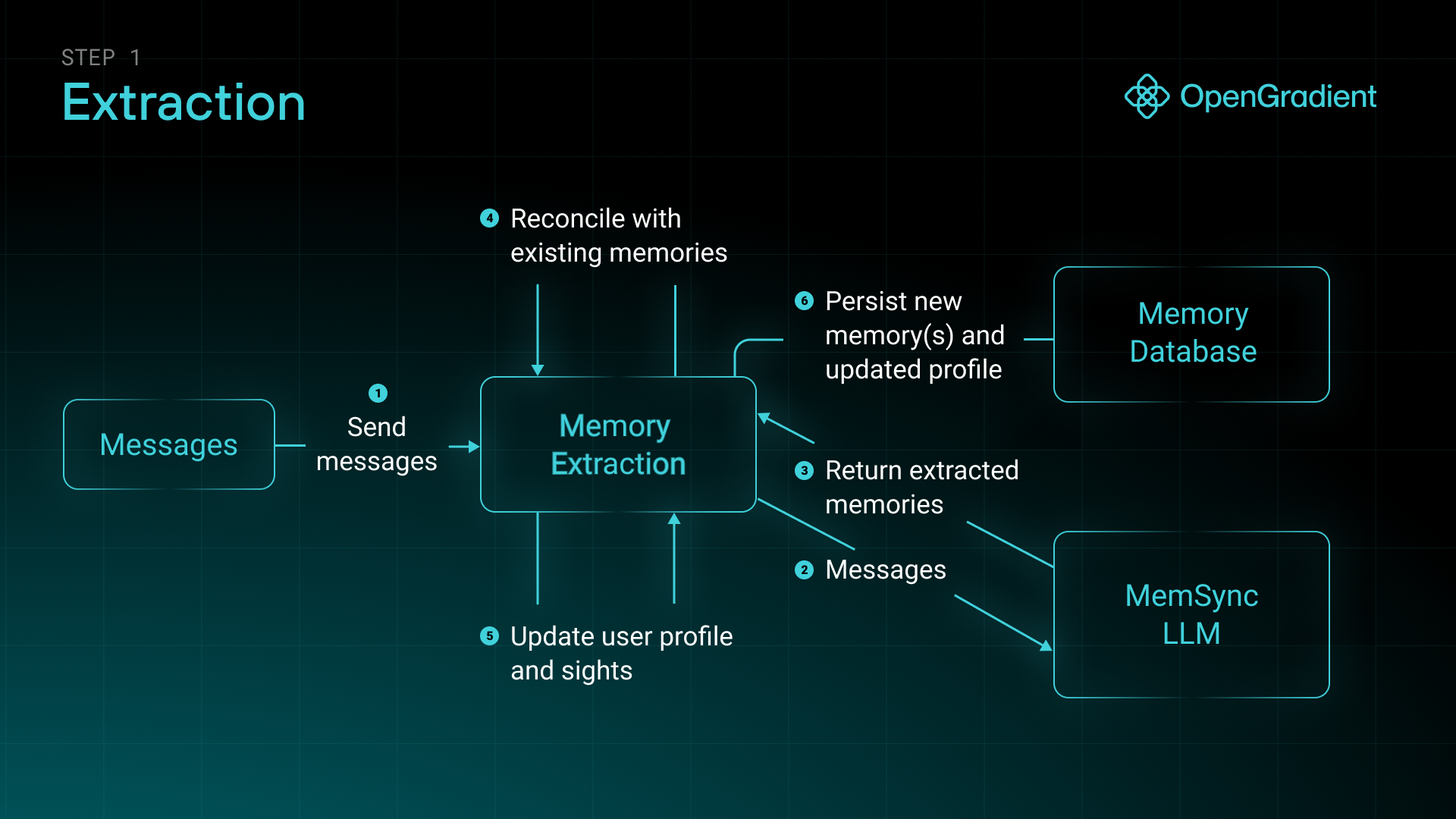
When researching the current existing solutions, we found a common pitfall is the accumulation of infinite data. Many memory systems end up amassing unwieldy amounts of data for which search becomes too unfocused. Similar memories are stored for the same user, and relevant context is pushed out by this frequently occurring data. Some systems overcompensate this by purely keeping only unique memories, but this loses out on the importance of emphasizing repeated memories.
For MemSync, we chose to solve both of these problems at once by utilizing four key operations.
- CREATE: Forms new memories from fresh information
- UPDATE: Modifies existing memories as situations evolve
- REINFORCE: Strengthens memories that prove repeatedly relevant
- DELETE: Removes outdated or irrelevant information
New memories that are too similar to existing ones are merged together through UPDATE. This enables us to continuously keep up to date with the most relevant information.
If the same type of content is ingested often, we begin using the REINFORCE operation. Each memory receives an importance score based on factors like frequency of occurrence, recency, and user context. This is later used during memory retrieval to give more context for the LLM to utilize when generating a response.
Formation: Detangling a Web of Memories
Memories aren't stagnant blocks of data. We don't record our lives as a camera roll of images. When we sleep, our brains often spend time reviewing the events of the day. We sit on thoughts, formulate new opinions, and merge ideas together to form insights that eventually form new memories.
Inspired by this thought, we designed MemSync to constantly think about the memories it stores. In the background, we utilize several techniques to derive interesting and insightful knowledge through the synthesis of multiple memories, as well as the incorporation of new memories over time. Where standard memory providers only widen across multiple conversations, MemSync continuously digs deeper.
Building a Living User Profile
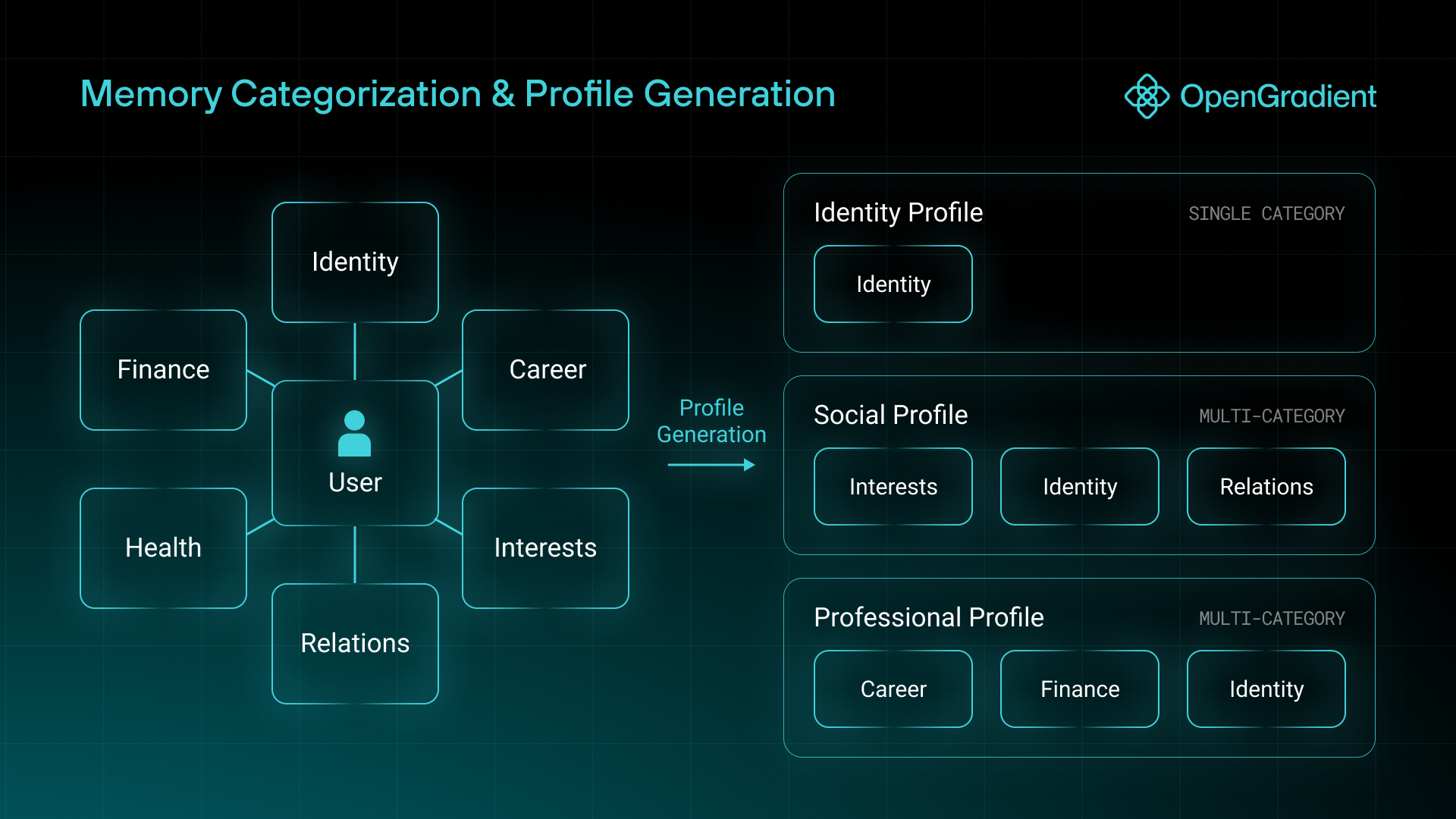
Beyond individual memories, MemSync generates dynamic user profiles by synthesizing data as it's captured. When you interact with your devices and applications, the engine identifies and extracts non-trivial information, simultaneously tagging it into a preset group of categories.
These tagged memories are then woven into concise, evolving profile snapshots – high-level summaries of user activity that dramatically improve memory retrieval accuracy in longer conversations.
These memory categories are used to generate insights and profiles for each user. Each memory can have multiple tags depending on their relevance into each category. We've experimented with groupings such as:
- Identity
- Career
- Interests
- Relationships
- Health
- Finance
- Productivity, etc.
These tags work to provide an easier way for us to sort information when the time comes to build summaries from the composite of multiple memories.
Once we have this extra metadata for each memory, we can work to create profiles for each user. Profiles are summaries of a specific facet of a user's personality. MemSync employs multiple profile types that pull from specific categories of memories. Some profile types will leverage a single category, such as
Identity Profile → Pulls only from the Identity category as this is a broad spread of memories
But some more complex profile types can end up pulling from multiple categories in order to get a more complete picture
Social Profile → Pulls from Relationships, Travel, and Interests depending on how relevant each memory is
These profiles build on each other as new memories come in. This allows us to efficiently consume new information without having to completely recompile each profile summary for each type. On top of this, these long-lasting profiles give the MemSync engine a much stronger ability to retain context between multiple conversations over long periods of time.
Retrieval: Perfecting the Pull Out Method
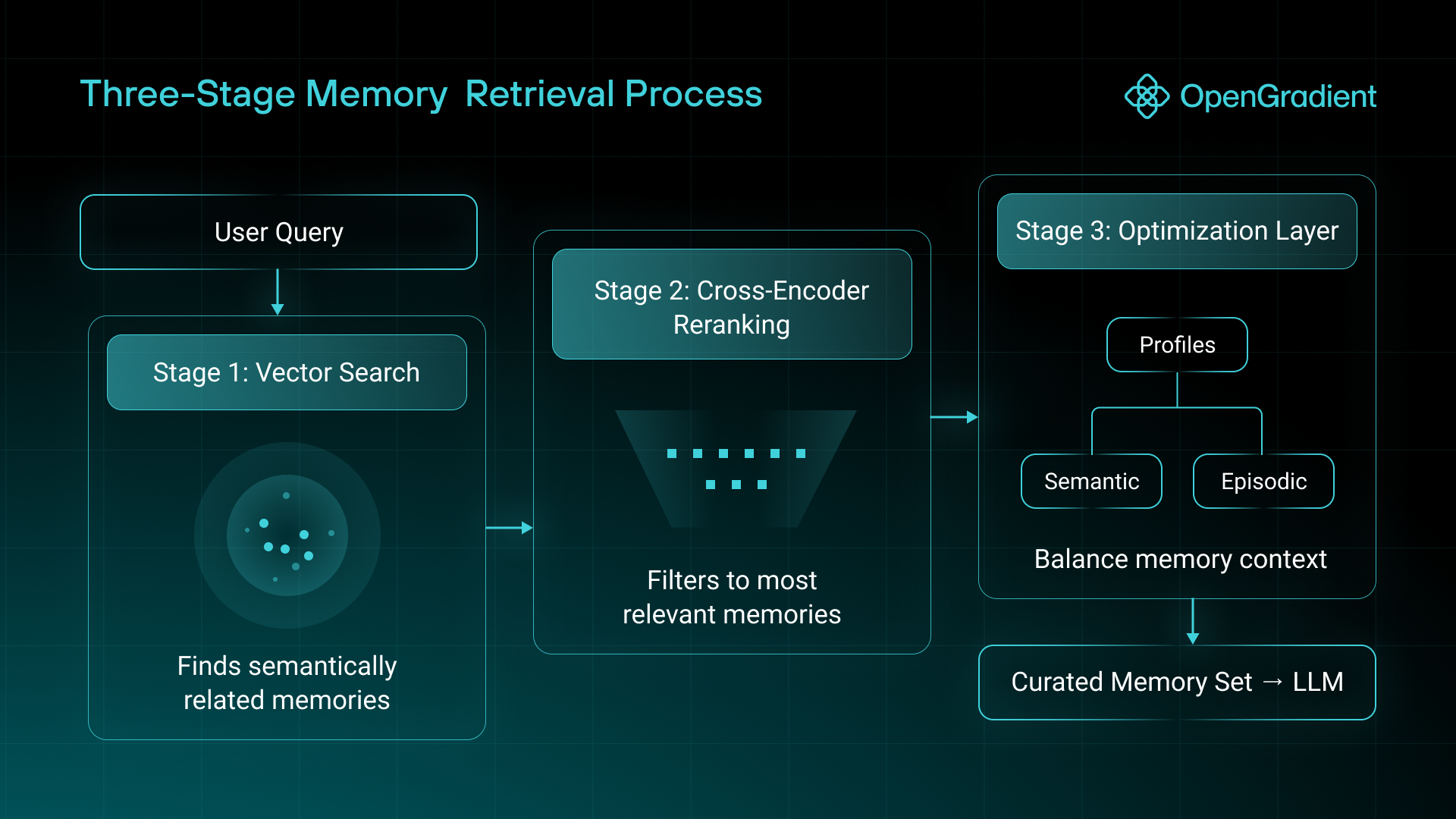
Now for the finale! How do we retrieve all of this excellent context and memory that we have stored? Vector search is not a new concept, and in fact has become wildly more popular in recent times due to its application in LLM memory systems. For MemSync, we decided to build on top of the efficient semantic queries of vector search to fully utilize all of the previous context-rich innovations that we implemented through a three-stage retrieval process.
Stage 1: Vector Search
When you ask a question or start a new conversation, MemSync first casts a wide net using vector embeddings. This technique finds memories that are semantically related to your current context, even if they don't share exact keywords. It also makes for an efficient search algorithm given complex memory and query content.
Stage 2: Contextual Precision Ranking
MemSync utilizes a specialized Cross-Encoder model that reads your query together with each potentially relevant memory, understanding not just similarity but specific relevance to your current query. Each relevant memory is then reranked based on this model's results and the given user query. The top n number of reranked memories are returned into the context window for the LLM to process as part of its response to a user query. This reranking process filters broad matches down to precisely what's needed for the conversation at hand.
Stage 3: Optimization Layer
To ensure users get a true balance of foundational and current memories, we actually run this vector-search and reranking process on both the pool of semantic and the pool of episodic memories. The split is experimentally based, but generally we prioritize more semantic memories over episodic memories, as non-temporally related queries can oftentimes not need any episodic memories at all.
We can now also ladle in the short user biography and multiple user profiles based on memory categories to give a longer-lasting context window that can carry the user's personality and current state into each prompt.
The final result? MemSync delivers a curated set of memories that paint a complete picture without overwhelming the conversation. By combining semantic memories, episodic events, and user profiles, we provide precisely calibrated context while leaving room for natural dialogue.
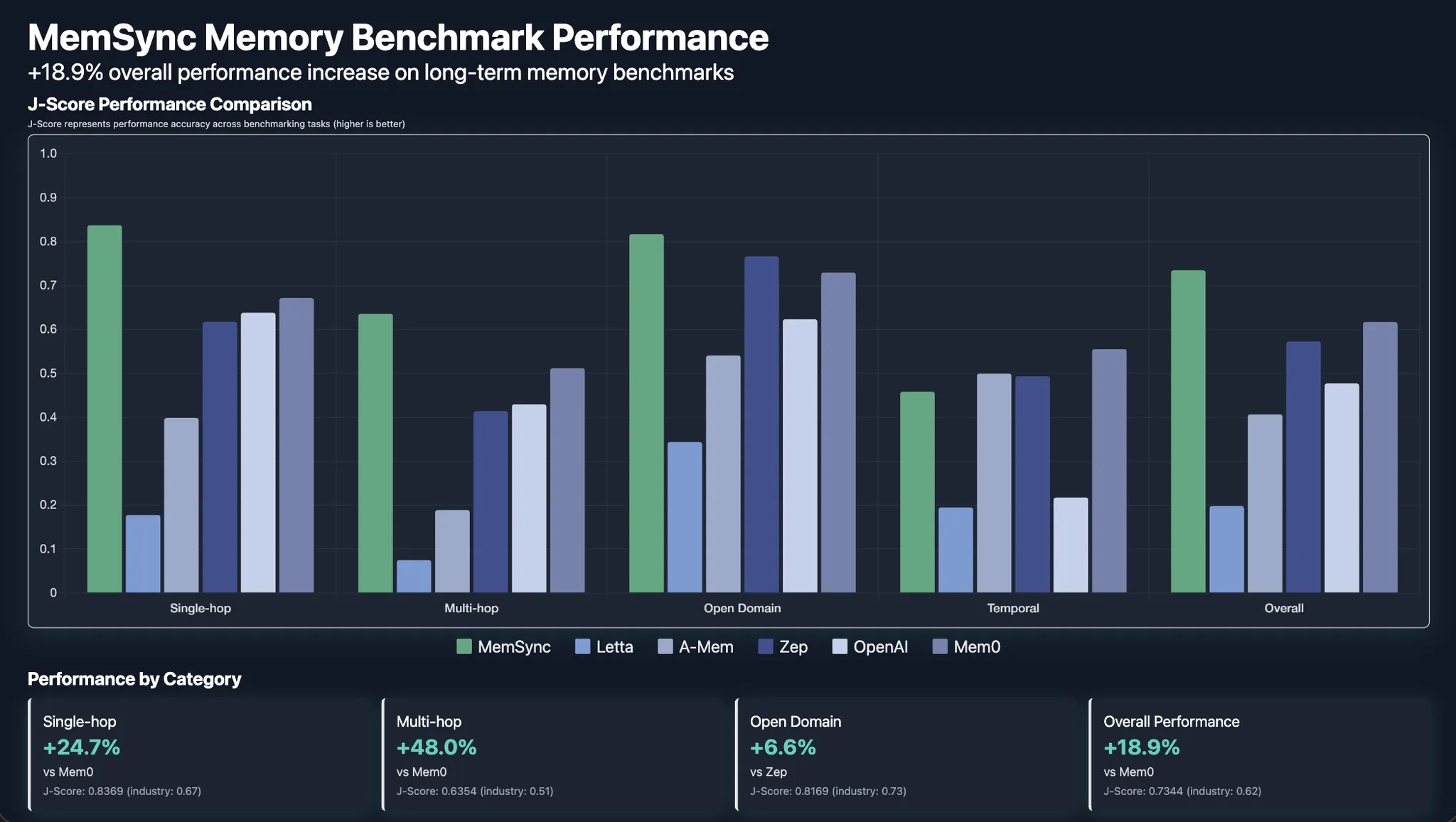
To prove the effectiveness of our product, we replicated Mem0's Locomo benchmarking and found that MemSync was superior to the other memory engines most prominently in the multi-hop category – which specifically required retaining details between multiple conversations over time.
Looking Ahead: The Future of Personalized AI
MemSync represents a fundamental shift in how we interact with AI. By providing persistent, intelligent memory across platforms, we're moving from stateless chatbots to truly personalized AI assistants that understand your context, remember your preferences, and grow more helpful over time.
Our architecture is designed to be portable and privacy-conscious, ensuring your memories remain under your control while seamlessly enhancing your AI interactions wherever you need them.
In the future, we hope to make this infrastructure even more extensible so that other applications that wish to utilize our memory implementation can easily employ MemSync into their own ecosystem.


